

I sell the shadow to support the substance.
—Sojourner Truth, 18641
Imagine a seven-year-old girl during a recent warm spring Sunday afternoon, daydreaming while standing at the window of the loggia on the third floor of her family’s apartment in the city center. The loggia faces the backyard, so the girl looks into the backyard’s garden. She arrests her gaze on the moving leaves of a horse chestnut tree in front of the window, and moves on to rest her gaze on the parked bicycle of the neighbor’s daughter, her best friend. She spots a black-and-grey cat walking across the green lawn towards the bicycle rack that frames the grass. The girl from the third floor wants to get a closer look at the cat.
She wants to rescale the cat so as to bring it from the distant backyard into the proximity of her eyes, which leads her to a techno-physiological automatism that she has internalized as a mental apparatus: While she looks from her window down into the garden—the window framing and fixing her gaze—she carefully touches the glass with her thumb and pointer finger as if it were a touchscreen. (Remember that the touchscreen became a globally popular technology in 2007.) The girl spreads her two fingers, moving them back and forth in what is called the “pinch-to-zoom” gesture, until she realizes that the glass she is looking through is not the touchscreen she was looking at just before. For a second, the girl loses her sense of orientation. Her feet re-ground quickly, yet articulate the need to seek another point of orientation. This is a condition that she shares with both the world-destroyer and the world-maker.
***
The pinch-to-zoom gesture is one of hundreds of patented finger movements for navigating one’s gaze on the touchscreen. It mobilizes the screen, transforming it into an “actionable image”2 whose dromological violence3 puts unbearable pressure on the emancipatory potency of thought that possibly resides in the exposure of an image as slow as an idea emerging from both inside and outside the image-frame. Yet, under conditions of navigation by means of computer-generated images, there is no more outside. Or rather, one has to look hard for an outside, reminiscent of how outer space seemed to be brought under control by the public circulation of the composite image of the earth as a blue marble on November 10, 1967. Under computational navigation, there is only an excessively nervous update of the frame that keeps the screen operator—finger and gaze—inside its image-space. The frame seems to become invisible under the pressuring premise of the inhuman commanding the frame’s infinite update, which transforms outside-matter or outside-life into an object of ignorance, protecting the single image’s sovereignty.4 Computational navigation engenders, as we will see, the capacity to destroy or create a world: If computer-generated images constitute the “ruling class of images” today, as Harun Farocki notably suggested, thus implicating the image viewer—or image navigator, a.k.a. screen operator—in the “production … or creation of a model world,” then how could we make sure that navigation does not re-model a world of class relations? Or, to ask the question differently, how could we—artists, theorists, filmmakers, coders—mobilize the “actionable image”—as an image of this ruling class of images—to navigate against its own ruling power?5 Could images as navigational tools create a better world, against or below the tools’ invisibilizing violence within this existing world? In other words, the girl at the window wants to make sure that we do not leave navigational tools to the world-destroyer. Instead, she wants to learn to make worlds, not only one universal world that the imperial navigator has claimed, but rather many worlds.
I will mobilize this approach by way of an utterly fragmented thought experiment, towards the urgency of unlearning the imperialism of navigation regarding computer-generated images as navigational tools. I will try to embark on some methodologies of “unlearning imperialism” through the recent writings of theorist, curator, and visual activist Ariella Aïsha Azoulay, who calls for a pedagogy of unlearning in regard to the imperialism of photography. The act of unlearning demands, suggests Azoulay, that we understand our own implicatedness in the histories of domination, which she describes as “our violent commons”; unlearning means foregrounding incongruences, such as “realities not aligned with concepts used to account for them”; unlearning means trying to transform such a troubled commons into a shared concern for making a common world.6
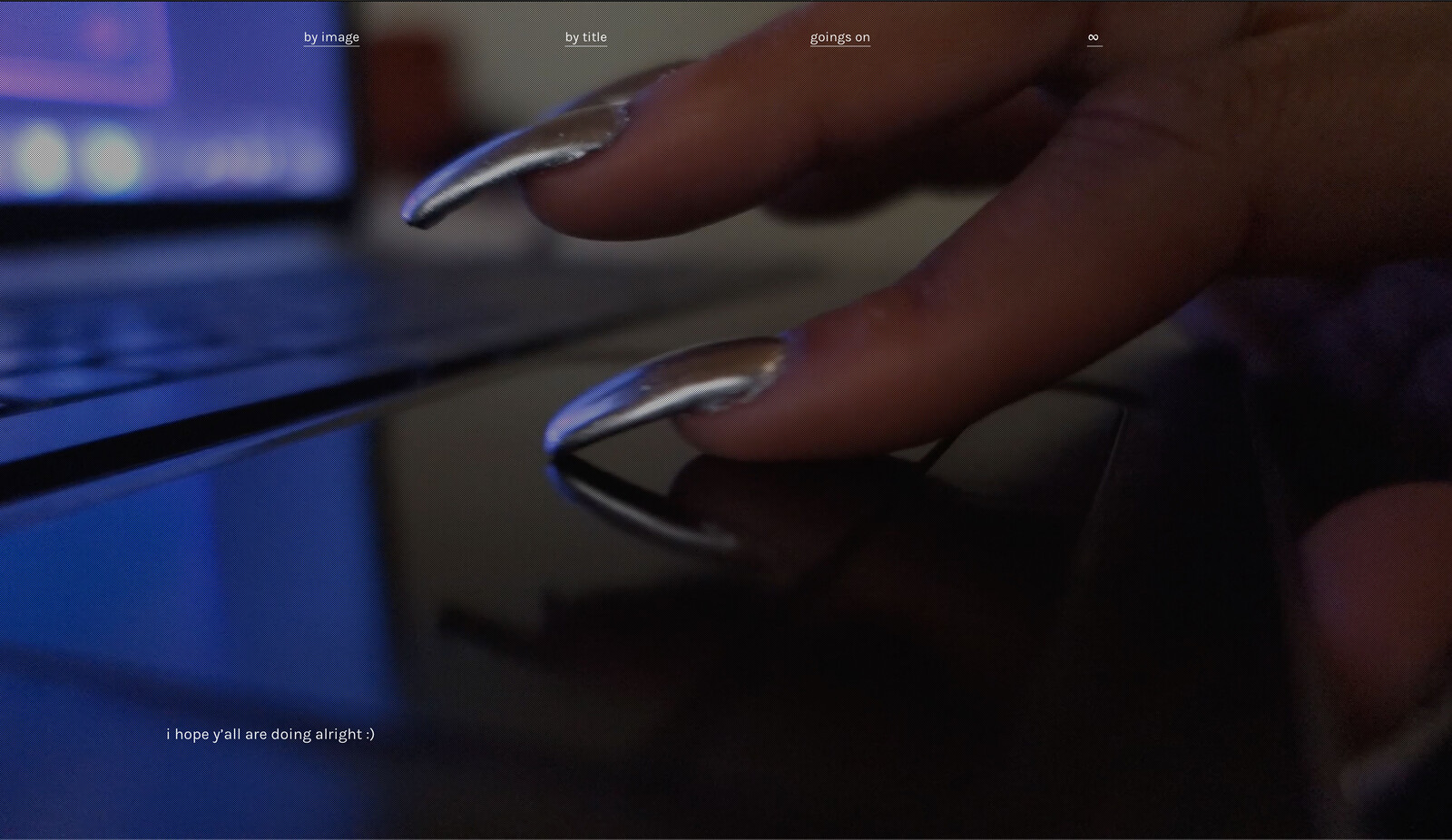

The pinch-to-zoom finger movement demonstrates the navigability of the image under conditions of computer animation rules.7 This gesture suggests a geospatial imaginary of world-making that fits onto the tips of two fingers, which scale the measurement at a distance into an “extreme proximity,” to use the words of artist-researcher Oraib Toukan.8 Since 2007, the touchscreen has become a popular display technology to zoom into a detail or set a focus on an image, to operate GPS maps or to order food via the phone. Hundreds of patented gestural movements for navigating, steering, and moving the image surface in real-time mark the scalability of the gaze by means of touch.9 These gestures have composed a sensory-motor vocabulary of the body, more specifically, of the finger’s tactile capacity that mobilizes the touchscreen interface as a display for becoming present within a world, yet without one’s own body. In the past, the gesture for picturing an image used to be expressed as a frame: the thumb and pointer finger of each hand, both spread apart to form an L shape, would form a pictogram marking the frame. It was an unambiguous sign—a representation of the image-cum-frame in which the view onto the world had to fit.10 Yet, the pinch-to-zoom gesture does not represent but rather exhibits or demonstrates the code of touch for operating the image within a navigable field—towards a geospatial imaginary beyond the limits of a static frame. The pinch-to-zoom gesture, which operates through the code of touch, recalibrates the frame continuously. Any seven-year-old child today whose parents have a smartphone has internalized this code. “The touch,” as Harun Farocki narrates in his film The Expression of Hands (1997), “originates in the casting of spells. The magical heathen object intended to be enchanted was only touched, not handled or held.” The touch is the least of all possible labor-exhaustive activities—kinderleicht in German, or, as light as a child’s muscle power—for scaling the eye’s distance while watching a cat, or for steering the gaze around an object of desire that can never be owned yet is possessed by the touch-steered gaze. Once the gesture turns into the linkage between two worlds—for example between those of the girl and the cat, or between the disciple and God—the sensory-motor gaze is as uncannily easy as the most powerful tool of control.
Regarding the magic touch as tool to navigate the gaze: Christianity has built its imperial power on the magic capacity of touch to animate a single image—the cross—as a world-making device. Each time, when the priest live-gestures or live-paints the cross icon into the air to steer or navigate a human creature’s banality of life on earth towards the Kingdom of God, God’s imperial power appears before the front of our eyes. Each time, this gestural hand movement reconfirms the building of a world within the existing one. This universal world-making within the existing world is visualized, for example, the Renaissance painting Salvator Mundi, likely painted by Leonardo da Vinci or his workshop around 1500, which registers—not by coincidence—as the most expensive painting ever sold. In 2017, an auction house in New York sold it to Prince Badr bin Abdullah bin Mohammed bin Farhan Al Sau, who is also the minister of culture of Saudi Arabia, for $450.3 million.11 It is no surprise that the buyer, alongside his involvement in the oil industry and real estate business, is also a primary stakeholder in media companies. The painting was realized during the Italian Renaissance (Quattrocento), which in Europe marked the transition from the Middle Ages to the colonial matrix of imperial modernity. Its title, Salvator Mundi, speaks first of its religious context. Yet also at stake is nothing less than the world itself: making a world within the already existing world. Divine redemption comes through the expression of the savior’s right hand—more precisely, through a half-open hand gesture with the pointer and middle fingers stretched out in order to bless the earthly sinners on the other side of the canvas. The fact that French king Louis XII commissioned the painting from da Vinci (assumingly) does not only speak to the proximity between Christianity and monarchy, but also invites speculation about the visual conditions of world-imperial imaginary preempting the First French Colonial Empire of the sixteenth century. One had to imagine a world before governing the world, before destroying the many different worlds within the existing world, before dispossessing the lands of these different worlds in the name of Christianity—fostering the cruel construction of colonial modernity, orchestrated by an arsenal of hand gestures navigating the organization of the gaze. Recent studies performed by computer scientists have revealed that the translucent orb in Salvator’s left hand is not made of crystalline solid, and is thus neither a crystal sphere nor a globe, but a 1.3 mm thin hollow glass ball.12 It’s reasonable to wonder whether the painter planted a subtle criticism of Christianity’s universal world claim into the painting, or whether it depicts a future dome for the king to fill. From today’s experience of navigating the visual screen through multi-touch gestures, the hand gesture of Trinitarian blessing, which symbolized the expression of amazement or wonder in ancient iconography, resembles various kinds of gestural movements such as the “double tap” or “press and tap,” which can be found under the “Trackpad” section of your MacBook’s system preferences. The code of touch programs the brain into a screen for producing a world.


Left: A reproduction of Leonardo da Vinci, Salvator Mundi, c. 1500; Right: A virtual model of da Vinci’s Salvator Mundi rendered using approximated geometry in Maya, a 3-D modeling and animation software, in order to experiment with a variety of configurations for the orb. This model was developed by computer scientists in the University of California, 2018/19.
Gestural recognition, or the touchscreen techno-sensorium, is one of many ways to navigate the image. Moreover, the use of images as navigational tools is not new. Ute Holl reminds us, for example, of the imperial dimension of the cinema and cybernetics. She points us specifically to the weaponization of image technologies during the Second World War, when “camera and radar eyes on airplanes and machine guns could not only record and transmit visual material, they could also calculate trajectories and guide projectiles,” leading to a militarization of the gaze.13 In this context, cybernetics was constitutive of a theory of communication under the conditions of the war against communism in the postwar world. Transdisciplinary exchange between neurological and mathematical research optimized military actions and protocols of control, with navigation guiding the hands—in small-scale tacticle movements—of soldiers, scientists, technicians, and politicians seeking to destroy the world from an extreme distance. Concretely, in War at a Distance (2003), the filmmaker and writer Harun Farocki describes the “HS 293 television bombs” of the early 1940s, developed during the Second World War by an Austrian scientist of aerodynamics for Nazi-German aerial warfare.14 The television camera–guided bombs, which were used as anti-ship missiles, confirm the conjuncture of cybernetics, militarization, and the image regime. If the code of touch, as described above, programs the brain into a screen to project images that kill (hence, that not only produce but also destroy the world), then the human capacity of looking cannot be subject to psychology alone but also involves technology and politics as part of its ontological-epistemological fabric. Knowledge and the conditions of knowing are both at stake. Like the girl at the window in the tale that begins this essay, we can’t leave technology to world-destroyers. Across our various practices, we have to research methods, vocabularies, and means for mobilizing a “psycho-technology” of images that can be navigated—images for being in this world, and for finding our way to the end of it. As Fred Moten has said, “I believe in another world in the world and I want to be in that.”15 To put it differently, the touch-steered gaze points us to the scalability of geopolitical relations stretching locality towards globality, and vice versa; it also assists in the conjuncture of two principle operational fields—human and machine—that usually remain separated through their own singular politics of matter, time, and space. This throws us in the middle of navigation as an ontological challenge: What would anti-imperial world-making look like? This calls for rehearsing the practices of unlearning: always already existing acts of resistance have proven that they can mobilize the means for world-making within the existing world despite technology’s genesis from cultures of imperial violence. For example, in Potential History, Azoulay writes that the camera’s shutter, a fundamental device of photographic production, exemplifies the extreme violence of photography: while the shutter is pressed, those potent histories that are unexposed to the light remain uncaptured. This while, I argue, speaks of a chronopolitics of uneven histories. Azoulay states that unpacking these uneven histories is crucial to the labor of unlearning photography’s imperialism. Still, the shutter does register shadows, and these shadows are the inscription of a fugitive knowledge that evades the shutter’s control. In this sense, shadows figure social practices of emancipation from the violence of “white science’s” color balance.16 Reading Azoulay’s book made me remember page forty-two of Teju Cole’s Blind Spot, where he writes about Sojourner Truth.17 In 1864, the abolitionist and feminist Sojourner Truth became the first person to publicly claim control over the political economy of her photographic image.18 In this well-known image, she is portrayed sitting at a table, likely in a photographer’s studio in Detroit. She pauses her knitting to allow the (unknown) photographer to take the picture of her; her gaze is directed at the camera, and thus the viewer, establishing a tripartite contract between herself as the photographed, the camera operator, and the viewer. At the bottom of the image (which exists in several layouts), Truth had the following sentence printed: “I sell the shadow to support the substance. SOJOURNER TRUTH.” The term “shadow” is a colloquial word for the photographic image, yet it also frames Truth’s pioneering courage to speak up, by means of photography, for her rights against the colonial matrix of power. Her statement about “selling the shadow” speaks of her rights to the image, both socially and materially. She owns not just the photograph, but her image, with the right to mobilize its value-making capacity to support her community. She has been portrayed sitting there by herself, yet she is not alone. In other words, the world of black feminist thought always already existed, despite photography’s capacity for a structural violence that installs a “differential principle” (Azoulay), creating a world where race and gender operate as value-making systems that serve the logics of racial capitalism. Today, we know about photography’s imperialism and capacity to make (or destroy) worlds. Sojourner Truth pioneered the practice of turning photography against itself, a few decades after photography was invented as a technical apparatus, in order to “sustain the substance,” that is, to speak to a substantially real world within the cruelly constructed existing one.19
***
They flow into our life montage, becoming the visual common through which we converse, the archive or inchoate lexicon of our expression.
—Jodi Dean, “Faces as Commons,” 201620
Imagine another Sunday in spring. This time, it’s early evening. Rain hangs heavily in the grey cloudy sky. The air is filled with a friendly breeze before the thick drops of rainfall to wet the walkway framing the plot of grass in the building’s backyard. The rain fills the horse chestnut tree’s flowers—which the girl she has learned to call “Kastanienkerze,” horse chestnut candle—with minerals and nourishment for its spring growth.
The girl has grown older. She is now twelve years old. She is on her own, but not entirely alone. In the next room, her mother is writing an essay for an art journal while her father prepares dinner. It is about 6 p.m. The girl is bored. She might help her father in a moment. But first, she takes her mother’s phone and plays with the MAD Arts app that her mother downloaded a while ago, initially for her daughter to use, but the mother has come to enjoy it too. The app allows you to create a proxy face for yourself, which will appear instead of your actual face when you video-call your friends, your relatives, or yourself (you can make the proxy face appear without calling anyone).
The girl had watched Avatar (2009) the week before. She vividly remembers Neytiri te Tskaha Mo’at’ite, the Na’vi tribe princess of the Omaticaya clan. Neytiri becomes the model for her proxy face. Blue skin. A well-formed, not-too-pointy nose. Large yellow eyes. Long, dark brown hair, braided into several small plaits that nestle against the head on both sides. She also chooses an elegant pair of earlobe plugs, similar to those of Neytiri. The girl enjoys smiling, moving her mouth as if she is speaking, raising her eyebrows as if she is surprised, making impish expressions—all to let the app’s facial-recognition software modify her portrait into a proxy face. She likes to take a picture of herself as “Neytiri,” which she then sends to her best friend, who sends back her own proxy face.
This time, though, something unexpected happens. Her mother must have updated MAD Arts recently, because when the girl switches from the front-facing camera to the back camera—which usually captures the space in front her—she still sees herself on the screen, but from behind! She is looking at the back of her own head! How is this possible? Somewhat anxious and scared, she looks at herself from behind like the figure in René Magritte’s La reproduction interdite (1937). She looks at herself from an outside of sorts, yet she remains inside the frame. She pinch-zooms, smart-zooms, rotates the phone—nothing helps. The black mirror of her mother’s phone has inverted its function, from an interface that serves as a portal of connectivity to the world outside, to an intraface: an internal interface that mirrors the girl from an imaginary outside, never allowing her to get out, or confront her face as common anymore.21
***
What could a practice of politicizing the image in the twenty-first century look like, considering that navigation—the computational condition of contemporary image-processing—updates, calculates, and incorporates the frame excessively and continuously into the image-making process? In order to render more palpable the beginning of a political ontology of image navigation by means of computation, we should remind ourselves of the principle of twentieth-century montage, which can offer a potent point of departure. Much has been written and produced in the name of montage. In 1967–68, film students, including Harun Farocki, announced the Dsiga Wertow Akademie, an occupation of their film school, the German Film and Television Academy in Berlin, an act that paid tribute to montage as a cine-political practice. Montage was pioneered by Esfir (Esther) Schub and Dziga Vertov, emerging from the world of Soviet cinema during the period of the Bolshevik Revolution of 1918. In other words, montage’s potency to mobilize the image for emancipatory processes was initially built from participation in communist world revolution. Would the latter reason, therefore, to consider the tripartism image–navigation–militarization (as mapped above) as constitutive for the navigable image to contribute to the “east-west formula” (Ute Holl), and thus to foment a global war against the world of communism? Does this “actionable image” uncannily complement the end of communism after 1990? Does this image, serving as a representative of the new ruling class and global capitalism, visually express the defeat of an originally world-revolutionary project? How do we mobilize navigation against its initial commitment to a capitalist modernity—disrespecting, refusing, and thus unlearning, its imperialism? A brief look into the montage principle might allow us to understand better what we have lost, or rather, what image-making elements need to be rearticulated through the navigability of the image.
Dziga Vertov’s proposal of montage as “interval theory” renders the frame an absolute necessity for organizing the movement of images into phrases, narratives, statements, and manifestations within a durational sequence. The frame marks the space-time between images and sounds; hence, it marks the excess of the seen—a space in which there is always already more to see beyond control. While editing tries to compose a narrative from images as smoothly as possible, montage insists on making the moments between frames palpable.22 The visible materialization of the frame institutes the image as a working instrument that creates a space-time of thought “from which some third thing [is] meant to emerge and which was conceived as a substitute for thinking,” as Ute Holl writes.23 It turns the image viewer into an image-thinker-cum-worker: she does not only watch the image at some distance from the screen, but she also “sees” the excess of the seen residing in the outside world. For example, in a 2019 episode of the television series Black Mirror entitled “Striking Vipers,” the main characters, Danny and Karl, need a frame in order to move from their living room into the VR world of martial arts and female sexuality. They need a portal, a frame, to enter the world of pure desire that, once they have arrived in it, moves as framelessly and seamlessly as possible. In the episode, one could argue that the role of the frame is played by the neural virtual gaming device called the Experiencer Disk: a small, round, button-like VR device that Danny and Karl attach to their temples in order to start playing the VR game Striking Vipers X, and that allows them to navigate the image in order to enjoy a world with “the best sex ever.” Once within the navigable field, the frame needs to become invisible. It needs to extend its borders beyond the eye’s capacity for controlling the field of vision, so that this new world can unfold into “bubble vision,” as Hito Steyerl describes the navigational gaze.24 Operated through the fingertips as they manipulate a joystick or a touchpad, the “bubble vision” is missing legs and arms, transforming the gaze into a gaze without organs, but one ruled by desire. It produces a model world that does not ultimately survive in the real world; however, this world nonetheless exists. Do we always have to search the navigational landscape for a frame of sorts, even though such a thing is supposed to remain invisible?


Danny Parker (acted by Anthony Mackie) enters the VR-fighting game Striking Vipers X, in the episode “Striking Vipers,” Black Mirror (2019).
In contrast to Vertov’s rather clinical approach, the filmmaker and editor Esfir Shub developed her understanding of montage through the practice of collective filmmaking, in which women—whom she calls Монтажница, or montazhnitsa—performed the editing work. Shub, whose writings have hardly been collected into a book yet, emphasizes the actual working conditions of editing itself: the agitative-educational function of the image does not begin in the moment of public projection, but in the editing room. “One more thing about montazhnitsy,” wrote Shub. “This collective of women workers delights us with its political harmony, social activism, and a sense of absolute camaraderie toward one another.”25 We might have lost the frame’s first imperative that confronts us with the limits of our knowledge—in other words, our own ignorance. But there is always a “meeting of two lines” that simultaneously separates and connects the single pixel, as the artist and research Oraib Toukan argues. I agree: computer-generated images still have a frame—thousands in fact, marking the “archetype of the sovereign,” as Toukan writes.26
Toukan’s desktop video When Things Occur (2016) is a wonderful example of taking a close look, rehearsing a certain intense proximity to the pixelated interface-frame that communicates Gaza to the world. In the video, Toukan has a series of conversations with several Palestinian photojournalists reporting on the war in Gaza in 2014. “The images that leave Gaza are always taken in hospitals or destroyed homes,” says photojournalist and writer Lara Abu Ramadan. While we hear Abu Ramadan’s voice, we see a kind of Photoshop animation of a photograph showing a living room under attack. The attack unfolds in a stuttering movement, caused by the limitations of the computational space. The image of the attack is dragged and dropped by a hand icon, which moves the file around and beyond the frame. Several sequences of When Things Occur show these types of photographs as raster graphics, revealing thousands of pixels separated from / connected to each other by a tiny thin line. Here we are; the frame exists. By seeing it, the vicious circle of reproducing the violence of victimization by means of digital circulation turns into a discourse, an analysis, and an infrastructure for conversation. One can see these tiny frames by zooming into the digitized or computer-generated image, as if looking behind the scene from the front; the extreme close-up disrupts the image’s representational function by imposing its own conditions of producing a discourse of abstraction. However, I wonder if the extreme proximity, which aims to create a more navigable field, also threatens to cause a kind of “acute myopia,” in the words of Reza Negarestani.27 To put it differently: yes, there might still be a line operating as a frame of sorts within the navigable image. But computer animation rules call for scalability—perhaps like the seven-year-old girl who confused the window for a touchscreen and tried to rescale the cat to bring it closer. First, the zoom-in that reveals the single pixel’s frame introduces a molecular scale of the image as abstraction. Second, the excess of the thousands of pixel frames per centimeter (pixel density) introduces a mass scale of practices of mediated communication. Therefore, this tiny, thin, separating-yet-connecting line, which only becomes visible in “extreme proximity” by using image-processing software to scale the image to reveal microscopic detail, enforces a “labor of invisibility.”28 Furthermore, computer animation rules also call for sociability. In this context, Esfir Shub’s invocation of “social activism” and “absolute camaraderie” resituates our focus onto the labor conditions that constitute the image’s politics: Can we mobilize the navigable field towards collective/social practice precisely by pointing to the actual working conditions of the navigable image, including its limits, horrors, and possibilities? This question brings us back to the urgency of unlearning the imperialism of navigation in visual-computational terms. Several contemporary works of art/research propose possible entry points for this approach, by resituating the “labor of invisibility,” bringing it within the invisible frame.29 This does not render visible the invisibilized or give voice to the silenced. Rather, it rearticulates the enmeshment of technology with politics, violence, images, and labor.
If the navigable or “actionable image” speaks from the ruling class of images in the twenty-first century, then we ought to move towards a potential present of navigation that rehearses methods of resituating computational image technologies against its imperial violence, “without forgetting, even for a moment, to what extent imperialism conditions us and invites to act as its agents.”30 Navigation puts pressure on the possibility to set thoughts free, to think outside of the box, and to unlearn the colonial matrix of the modern knowledge system. Therefore, the question here is not only who the workers are under computer animation rules, but also where the workers are on the measures of scale between extreme distance and extreme proximity of world-making. Navigation beyond control invokes thought-turbulences as well as awkward gaps; it calls for social activism while navigating as a mode of making. For embarking on such world-modeling, the tasks for operating today‘s navigable images entails learning to articulate the feedback loops, back and forward, between the code of touch that steers the gaze and formats the brain into a screen; it fosters the conditions to confront the horror of immersion and to collectivize the politics of invisible labor across many locations, as planetary computation pledged, towards a possible anti-imperial navigational landscape.
Quoted in Teju Cole, Blind Spot (Penguin Random House, 2017), 42.
Harun Farocki proposed the notion of the “actionable image” in his lecture “Computer Animation Rules” at IKKM in Weimar on July 7, 2014, after encountering Alexander Galloway’s concept of the “actionable object” in his Gaming: Essays on Algorithmic Cultures (University of Minnesota Press, 2009).
In Politics and Speed (1977), Paul Virilio develops the idea of “dromology,” which he defines as the “science (or logic) of speed.” He uses the term in the context of discussions about technical vitalism and the militarization of society.
Introducing the notion of inhuman here relates to Reza Negarestani’s proposal of “inhumanism,” or the machinic, which, as I understand it, suggests an approach to unsettle the humanist imperative of European enlightenment, or the anthropos, in relation to a politics of thought as a modern system of knowledge.
Farocki, “Computer Animation Rules,” 2014.
Ariella Aïsha Azoulay, Potential History: Unlearning Imperialism (Verso, 2019), 38. In this book, Azoulay argues that we need to re-historize the invention of photography, seeing it as not solely a technological medium, but as an instrument of domination employed by the centuries-long, massive violent projects of imperialism, colonialism, and slavery.
Harun Farocki, “Computer Animation Rules,” 2014.
Oraib Toukan, “Toward a More Navigable Field,” in “Navigation Beyond Vision, Part 1,” ed. Doreen Mende and Tom Holter, special issue, e-flux journal, no. 101 (June 2019) →.
In February 2008, less than one year after Apple introduced the multi-touch technology for consumer products, around two hundred patents had already been filed for the iPhone alone. See Bryan Gardiner, “Can Apple Patent the Pinch? Experts Say It’s Possible,” Wired, February 2008 →.
Harun Farocki uses his hands to form a frame in many of his films—for example in Interface (1996) and The Expression of Hands (1997). The frame-gesture also plays a role in Abbas Kiarostami’s Life and Nothing More (1992).
The current whereabouts of the painting reads like a detective story of the global art trade. It was meant to be on display at the Louvre Abu Dhabi in 2017. Yet so far it hasn’t turned up. Some stories say that it has been exhibited on Prince Badr’s yacht. It has also been reported that the real buyer behind Prince Badr is Mohammed bin Salman, the crown prince of Saudi Arabia and the deputy prime minister of the country.
Marco Zhanhang Liang, Michael T. Goodrich, and Shuang Zhao, “On the Optical Accuracy of the Salvator Mundi,” December 2019, arXiv:1912.03416.
Ute Holl, Cinema, Trance and Cybernetics (Amsterdam University Press, 2017), 74.
In War at a Distance (2003), Harun Farocki shows images of a test flight involving the television bomb, and states that it was never used in combat.
Stefano Harney and Fred Moten, The Undercommons: Fugitive Planning & Black Study (Autonomedia, 2013), 118.
The art critic Brian Wallis analyzed daguerreotypes portraying slaves named Renty and Delia in South Carolina in 1850, taken by a Swiss photographer who sought to justify racial segregation by visual means. See Wallis, “Black Bodies, White Science: The Slave Daguerreotypes of Louis Agassiz,” Journal of Blacks in Higher Education, no. 12 (Summer 1996): 102–6. (To deprive him of the valorizing economy of visibility, I cross out the name of the Swiss photographer, whose name still adorns streets and mountains in Switzerland. Thanks to antoine simeão schalk for alerting me to the latter.)
In addition to Cole’s book, see Sojourner Truth, Narrative of Sojourner Truth, 1850.
Azoulay mentions but does not elaborate on Sojourner’s act of speaking truth to visual power. But she does discuss the lawsuit that Tamara Lanier brought against Harvard University regarding the 1850 photographs of Renty and Delia, who she claims are her ancestors. See Azoulay, Potential History, 146.
See Glenn Ligon, I Sell the Shadow to Sustain the Substance (2006), a neon light installation inspired by Sojourner Truth.
Jodi Dean, “Faces as Commons: Secondary Visuality of Communicative Capitalism,“ Open! Platform for Art, Culture and the Public Domain, 2016.
The vocabulary used here is adapted from Alexander Galloway, The Interface Effect (Polity, 2012); Benjamin Bratton, “The Interface Layer,“ in The Stack: On Software and Sovereignty (MIT Press, 2015); and Jodi Dean, “Faces as Commons.”
“Montage is noticeable as montage, editing tries not to be noticed.”—this is how Harun Farocki summarized the East-West formula for West Berlin students. Quoted in Holl, Cinema, Trance and Cybernetics, 27.
Holl, Cinema, Trance and Cybernetics, 28.
Hito Steyerl, “Bubble Vision,” lecture, January 28, 2018, STAMPS School of Art and Design.
Quoted in Alla Gadassik, “Ėsfir’ Shub on Women in the Editing Room: ‘The Work of Montazhnitsy’ (1927),” in Apparatus: Film, Media and Digital Cultures in Central and Eastern Europe, no. 6 (2018).
Toukan, “Toward a More Navigable Field.” Updating the frame is computed by frame-per-second (fps) as well as by the unit of “chunk” in video-gaming such as Minecraft. The higher the fps, the better the fluidity of the navigational image and the faster the action; the higher the rate of chunk the better the rendering of distance and more quickly exhaustible the memory space as well as energy.
Negarestani uses this phrase in the context of a discussion about his geophilosophical understanding of the regional-universal relation. See Reza Negarestani, “Globe of Revolution: An Afterthought on Geophilosophical Realism,” Identities 8, no. 2 (Summer 2011): 25–54.
Thomas Elsässer, “Simulation and the Labour of Invisibility: Harun Farocki’s Life Manuals,” animation: an interdisciplinary journal 12, no. 3 (2017): 214–29. Elsässer’s approach does not, however, problematize technological labor in regard to gender politics. For this, see the work of theorists and writers Sadie Plant and Wendy Hui Kyong Chun, who examine the proximity between invisible labor and female labor in computational technologies.
I am thinking of the video installations Serious Games (2009) and Parallel 1–4 (2014) by Harun Farocki; the desktop documentary Transformers: The Premake (2014) by Kevin B. Lee; the video essay Against the POV (2016) by Clemens von Wedemeyer; the performance In Rotation for Projection and Monitor #1 (2017) by Sondra Perry; the desktop video Nucleus of the Great Union (2018) by the Otolith Group; and the spatial audio performance ANXIETIN (2018) by Hannah Black, Bonaventure, and Ebba Fransén Waldhör, among others.
Ibid., 20.
Category
This text is dedicated to filmmaker, writer, and friend Harun Farocki (1944–2014). I would like to thank Julieta Aranda, Kaye Cain-Nielsen, Kodwo Eshun, Brian Kuan Wood, Charles Heller, Tom Holert, Volker Pantenburg, and Susan Schuppli for conversations on navigational problematics, as well as the students in the CCC RP Master Program at HEAD Genève, specifically those participating in the Curatorial/Politics seminar researching the question “What is Navigation?”