

The connection between the 2019 CGI The Lion King remake and an automated vacuum cleaner might not be apparent, but behind the scenes there are a surprising amount of commonalities. While The Lion King was praised for its realism, automated vacuum cleaners are ridiculed for their inability to navigate the home. Both, however, rely on virtual environments, digital twins created in game engines to replicate the real world. While Hollywood experiments with the use of game engines to simulate “on location” shooting of CGI movies, the game engine Unity offers computer vision training dataset generation and testing within simulated worlds.1 According to Danny Lange, Unity’s senior vice president of AI, “The real world is so freaking limited. In a synthetic world, you can basically re-create a world that is better than the real world for training systems.” Virtual worlds need to be populated with stuff though to look realistic. But these virtual objects all come from somewhere, someone, something.
Ever since her wildly famous book, the internet has wondered “Is Marie Kondo’s home still tidy?” Apparently, in the organizing consultant’s own words, her home is now messy.2 The KonMari method of organizing one’s belongings by category and only holding on to items that spark joy could deceive as a marketing campaign by the smart home industry. An automated vacuum cleaner’s biggest threat, after all, is stuff scattered across the floor. The vacuum’s brushes and wheels get tangled up in electrical cords, loose themselves in piles of clothes, get stuck in hair, or fail to recognize dog poop, distributing it everywhere and mapping out its chaotic path along the way.


Jon Favreau (left) and his team controlling cameras and moving within the virtual The Lion King film set. Image courtesy of MPC, Technicolor.
When Dyson announced its new high-end automated vacuum cleaner equipped with four cameras in March 2023, internet commentators really just wanted to know “the answer to a Really Important Question: Can it avoid smearing dog poop all over the place?”3 Appropriately, iRobot dedicated its entire advertising campaign for the j7+ model to the improved object recognition capability called P.O.O.P., short for “Pet Owner Official Promise.” In a series of video adverts, a Roomba encounters unknown objects. Upon detection, the video cuts to a control room that looks similar to a Real Time Crime Center where a handful of “officers” are watching the Roomba’s camera feed, frantically deciding what to do with the unrecognized item and ultimately deciding to circle around it. Euphoria ensues over the successful mission. Emotions are so jubilant that it could have been the first moon landing.
The control center metaphor was presumably chosen to convince consumers of the Roomba’s (improved) command of its assignment. But is it an analogy, or a Freudian slip? What exactly are Roomba cameras recording? How wide is its viewing angle? Where is the video data stored? Does footage analysis take place within the vacuum cleaner’s hardware, or is it shared via a cloud service for processing? The privacy implications of these uncertainties are substantial, considering the device roams around in your home. The journalist Eileen Guo reported in detail on screenshot leaks recorded by Roomba cameras, whose content varies from a woman sitting on a toilet to a boy lying on the floor on his stomach, peering at the camera, and various other views.4 “Rooms from homes around the world, some occupied by humans, one by a dog. Furniture, décor, and objects located high on the walls and ceilings are outlined by rectangular boxes and accompanied by labels like ‘tv,’ ‘plant_or_flower,’ and ‘ceiling light.’” What Guo uncovers along the trail left behind by the screenshots is the network of processes and actors involved in training cameras to recognize objects. The leaked screenshots were captured by Roomba development versions roaming around in volunteer’s homes to test out new features and firmware updates. One of those features was improved object recognition. But how exactly did it get better?


Every possible scenario
Part of this progress can be ascribed to supplemented or new training datasets comprised of thousands of images of the objects and environments the vacuum cleaner will likely encounter. These images can be photos, but more often are frames exported from videos recorded by cameras on board the device itself, which are ultimately assembled into a shared training dataset. To extract information from these images, visible objects are manually annotated and sorted into label classes. This labor is frequently outsourced by the vacuum manufacturer to third party contractors like Amazon Turk or ScaleAI, which distributes tasks among remote workers with often precarious and unfairly remunerated working conditions.5 In the case of the Roomba footage, the leaked screenshots ended up on a Facebook forum set up by a group of annotators to discuss ambiguous images and collectively decide on object labels. The process of manually labelling footage is incredibly arduous and time consuming. Annotation can take up to ninety minutes per frame, and ambiguities will remain. On top of that, not all information that a computer vision system needs to be trained for is available as thousands of images. Colin Angle, CEO of iRobot, put it bluntly: “I don’t know how many Play-Doh models of poo we created. Many, many thousands.”6
As an alternative to sculpting various eventualities out of Play-Doh, desired training images can be rendered from digital environments. Part of a digital replica’s selling point in place of camera footage is the avoidance of manual annotation: digital models come with file names and are placed in virtual environments with a clear source path. Everything is constructed. Everything is already labelled. However, digital training data should not be mistaken as objective. On the contrary, human labor—and with it bias, assumptions, and cultural context—are nonetheless part of computer vision. 3D assets need to be modeled or sourced from somewhere. Availability and imagination determine synthetic training data.
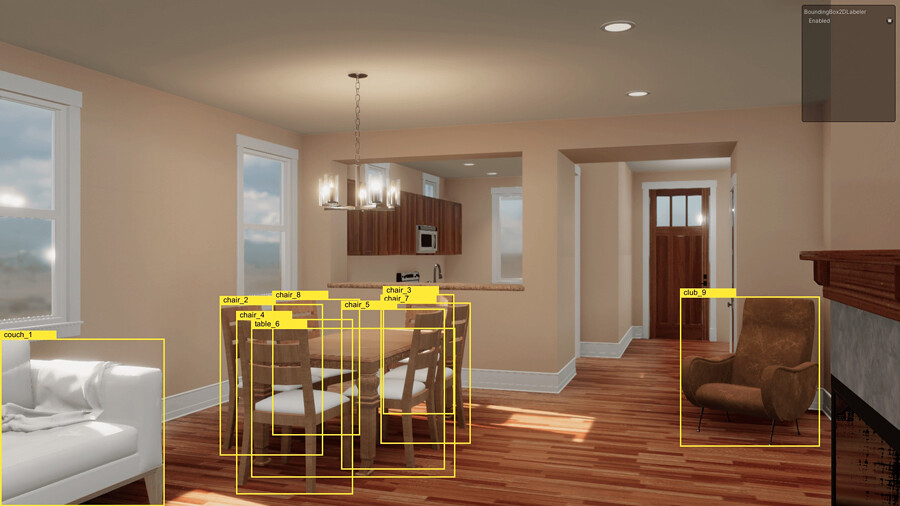

Unity Computer Vision Datasets (Home interior sample) “The 2D Bounding Boxes precisely locate and label objects in screen space for recognition.” Source: Unity.
Virtual replicas are also marketed as contingency machines. They have the advantage of simulating situations that are difficult to capture in real life and churn out rendered visualizations. Think of a self-driving car that needs to recognize various objects crossing the road in different light and weather conditions. In one research from 2016, 25,000 frames were captured from Grand Theft Auto V as a proposal for a synthetic training dataset.7 While virtual worlds offer the possibility to create variations of a scene, the material excess, personal modifications, ambiguities, and randomness of life is absurd to imitate. Los Santos, the virtual city from GTA that is roughly based on Los Angeles might be a welcome ready-made digital twin for a self-driving car training dataset, but would The Sims be a fitting ready-made digital twin for domestic space?
At the electronics trade show CES 2023, the booth of the smart home company Ring was set up as a replica of an all-American suburban home: a wooden fence complete with gate, a stone-paved walkway leading up to a white house, and grass so perfect it looks like a CGI render. Through a large window visitors could see a demonstration of the company’s new autonomous drone camera. What initially looks like a living room unravels upon closer inspection as an empty house with photo wallpaper—a domestic backdrop, a flat user interface. While this might have been a choice to demonstrate a prototype that isn’t quite ready to fly among people and furniture, it eerily hints at an ideal habitat for computer vision. But the home is not, at least not yet, an augmented reality experience.


I died 60 thousand times to get there
There have long been various attempts at creating rich virtual worlds imitating life, such as the doomed Metaverse or the long-running online community Second Life. At first glance, virtual environments for domestic computer vision training look oddly similar. The challenge these projects face is creating a replica of the physical world. Rather than immersive games that offer an escape through imagination, fantasy, and role-play, the success of these virtual environments are measured by their similarity with reality. “Photo-realistic” is a mark of ultimate “twinning” with the real world. The digital twin shall become the territory.
The indoor scene dataset InteriorNet is described as superior to other datasets because it features “daily life noise.”8 That “noise” was achieved by collaborating with Kujiale, an online interior design software with a large 3D asset database of furniture and home accessories. By using Kujiale’s “product catalogue,” the assumption is made that “product equals home.” While it is true that domestic spaces fulfill similar needs across the globe, the expression of these functions might not be as uniform. A kitchen does not look the same everywhere, nor does a bed. That is true for cultural rituals, family structures, and personal preferences. Geographical differences have pushed global furniture manufacturer IKEA to shift to a product catalogue that almost entirely features digitally rendered images, rather than product photography, to respond to local market preferences without labor intensive physical redesigns.9
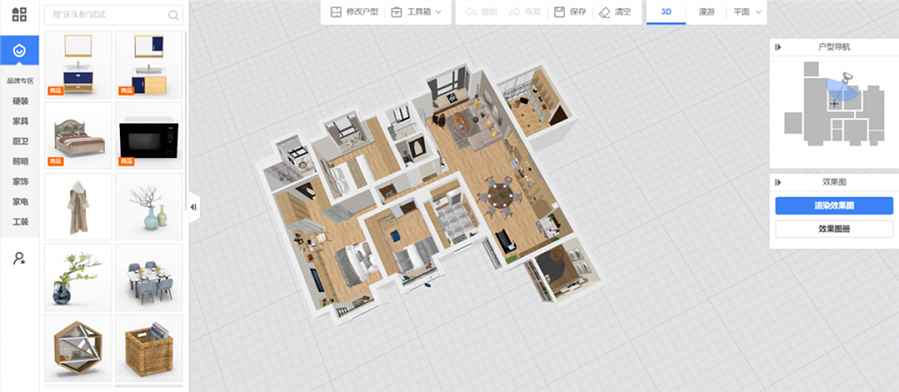

Screenshot of Interior Design Online Platform Kujiale.
While a training dataset’s content has a specificity to it that either is intentional or the result of assumptions, its associated research papers tend to not mention cultural context or explicit application. A training dataset might be assembled for a specific research question, but the resulting computer vision model can be used for very different applications and the dataset re-used or modified elsewhere. To avoid uncertain sources and intentions, rigorous documentation is crucial for ethical machine learning research and development. Towards these ends, Margaret Mitchell et al. proposed “Model Cards” in 2018,10 while Timnit Gebru et al. developed “Datasheets for Datasets,” which recommended that “every dataset be accompanied with a datasheet documenting its creation, composition, intended uses, maintenance, and other properties.”11 While such documentation is essential for ethical and legal concerns, it cannot record assumptions that are so embedded in knowledge that they become common sense. That is not a shortcoming of a documentation framework, but rather an impossible task, as common sense is so engrained that it is taken for granted. The computer scientist Yeijin Choi speaks of the absurdity that ensues through AI’s lack of common sense:
Normal matter is what we see, what we can interact with. We thought for a long time that that’s what was there in the physical world—and just that. It turns out that’s only five percent of the universe. Ninety-five percent is dark matter and dark energy, but it’s invisible and not directly measurable. We know it exists, because if it doesn’t, then the normal matter doesn’t make sense… You and I know birds can fly, and we know penguins generally cannot. So AI researchers thought, we can code this up: Birds usually fly, except for penguins. But in fact, exceptions are the challenge for common-sense rules. Newborn baby birds cannot fly, birds covered in oil cannot fly, birds who are injured cannot fly, birds in a cage cannot fly. The point being, exceptions are not exceptional, and you and I can think of them even though nobody told us.12
A computer vision system takes an image of a bird with leopard fur at face value, and its analysis will depend on the training data it was developed with. Will it give priority to the shape of the bird or to the texture of the fur? In other words, will the computer vision system “see” a bird (shape), or a leopard (fur)? Presenting the same image to a group of people instantly unveils it as a fictional animal. Birds don’t have leopard fur. That’s common sense.
Hypersim is a dataset released by Apple in 2021 that handles the ambiguity of an object’s function, shape, and use by creating a label category called “otherprop”: a container for all things that don’t fit neatly into other classes. But what in the language of computer vision research is simply called “noise” or “other” is in reality life itself. The miscellaneous memorabilia with emotional value that can’t be rationalized defeats the logic of categorization. Even Marie Kondo proposes to have a box of random items that aren’t used often but can’t be parted with. Their value is other than their physical form. You don’t need that movie ticket anymore but keep it for sentimental reasons. Looking at its function, the ticket is trash; the movie screened in the past. Pure logic renders the ticket useless. Yet, in a case where an automated agent’s decisions are based on the information “learned” in a virtual world, what logic applies? Would the ticket be categorized in the virtual world as “document,” “otherprop,” or simply not exist?


iRobot’s experience with poop is a good case study for the scenario that can ensue if an object is not recognized: utter chaos. Comical, but not fun. iRobot’s response to this was scale; more data. But as mentioned, a major hurdle in creating high resolution synthetic environments is the sheer labor involved in creating digital assets. As a result, workflows are constantly tweaked and developed to circumvent extensive modeling. One strategy has been to enable smartphone users to scan objects as seamlessly as taking photos, which when uploaded to a backup cloud server (with or without consent) or an online sharing platform, could grow into a repository as large as the image hosting service Flickr and be used as training data (which has in fact become Flickr’s fate).13 As a way of getting around the various issues of user participation, game design studio Embark has developed an Asset Processor, an in-house tool within the 3D software Blender that can create a scan from an online video, use it as a model reference, and create a game ready high-resolution asset.14 Conflating several laborious steps into a single click, their aim is to free their game designers from work that is repetitive and time consuming such as texture mapping or scan cleanup, so they can spend energy on creating the game world that is to be populated.
While these options rely on capturing at some stage in the process, procedural modeling—a generative technique to create models based on sets of rules—can do without and offers even faster asset production. In today’s visual culture, the meticulous work by Bernd and Hilla Becher documenting typologies of industrial buildings and structures could be mistaken as procedurally generated rather than photographically documented. Embark’s interest in developing an efficient content generation workflow extends to animation, which requires even more time intensive labor and is therefore particularly attractive to automate, at least partially. The on-going development to eliminate manual animation workflows is a good example of the designer’s new role amid a stream of generated content. According to Tom Solberg, an engineer at Embark, “we’re not dependent on an army of animators to script every single movement and encounter that we put in the game. In fact, our aim is that our designers should be able to teach agents without input from engineers or animators at all.”15 The agents referred to here are in-game characters, and the workflow described is one where the designer sets the rules and tweaks them to the desired result rather than manually modeling and animating every aspect. Automating part of the process slightly shifts the role of the designer to an editor. Many variations of characters can be generated procedurally and selected to be placed in-game. The characters then proceed to learn to walk and (re)act through machine learning. One of these characters, a spider-like hexapod called Wasabi narrates documentation footage of its learning process: “I am Wasabi. I learned to walk on my own. I died 60 thousand times to get there. I make mistakes but they make me better by the hour.”16 What defines “better,” however, is dependent on the rules set by the designer.
Thinking back to Yejin Choi’s description of AI’s lack of common sense, humans perceive domestic objects not just according to their shape, but also their function, value, and use. Even those attributes, however, are not always so clearly defined. The linguist William Labov characterizes words as “shifters” that change meaning and escape simple description. Furthermore, according to Labov, the objects that words refer to are even more slippery to define. He outlines the creativity necessary to express an infinite number of objects in the real world with a finite set of words; a creativity that is arguably lost in training dataset labels where words and objects are encoded to each other. To demonstrate this and explore the “fuzzy borders” of words and their meaning, Labov proposed a “cup experiment” in 1973.17 Participants were shown line drawings of various bowls, cups and vases and asked to name them based on their shape. As a next step, participants were asked to imagine the various containers in different scenarios: someone stirring a spoon and drinking from it, on a dinner table filled with mashed potatoes, and on a shelf containing cut flowers. They then responded whether their initial object identifications held up, or the extra information shifted their perception. The experiment’s results demonstrated that each scenario changed an object’s name. Object recognition is context sensitive. Containers associated with food were named “bowl” or “cup,” while a relation to flowers resulted in “vase.” While context is crucial, Labov’s experiment was still dependent on his specific research dataset; as a general model applied in the wild it quickly falls apart. Meret Oppenheimer’s Object (1936), a fur covered cup with saucer and spoon would crash Labov’s calculation.


“Shell” ware by Griffen, Smith & Co., Phoenixville, Pennsylvania ca. 1879–90. Earthenware with majolica glazes from the private collection, most ex coll. Dr. Howard Silby. Photo: Bruce White.
Describe what you want
While procedural generation produces variation, variation does not equal diversity. It’s output scales in amount, but does not guarantee difference within that information. According to the sociologists Alex Hanna and Tina M. Park, “scale thinking requires users to be of the same kind, or within a narrow set of predefined bounds, which is most often to the detriment of people ‘at the margins,’ marked by systems of racism, transphobia, and ableism.”18 These “predefined bounds” can be illustrated through the content of a training dataset, or Labov’s experiment which functions well within his research data but falls apart outside of it. The territory of digital twins is a highly exclusive world, discriminating against anything and anyone outside the predefined bounds of the dataset.
Still, virtual environments can in some instances be useful tools to model eventualities. What is crucial however, and often missing, is annotation of the data source, a clear description of its intended application, its cultural context, and limitations. Synthetic content generation is becoming ever more automated, and large amounts of output should not be mistaken for diversity. Scale is not a fix against discrimination. As far as synthetic datasets of (domestic) interiors go, generating various pieces of furniture and home accessories seems harmless enough. Yet, even if synthetic interior datasets for domestic computer vision mostly lack explicit human representation, a (standardized) person is lurking in the function and ergonomics an object implies.
Recent possibilities to “prompt” content—to describe in “natural language” the visual output one desires—presents a tool to trace the boundaries of a dataset. One of a few recent models, Luma AI’s Imagine 3D is a text-to-3D pipeline to generate 3D models from a text description, which is easy to speculate functioning alongside, or even replacing procedural modeling. Yet my language is not your language. Prompting Luma AI with “main character” generates a muscular white male figure with dark short hair, a beard, green T-shirt, jeans, and white sneakers, his fists clenched. “American dream, inspiring” generates a white armchair. My main characters don’t look that way; my dreams are different. Any prompt can be written, but the response will always be dependent on the training data. Rather than generating a world beyond imagination, prompted content exposes defined parameters. Rather than generating “your text description,” these models reveal what they know.
Nick Summers, “Inside the virtual production of ‘The Lion King,’ engadget, July 30, 2019. See ➝. Borkman, Steve, Adam Crespi, Saurav Dhakad, Sujoy Ganguly, Jonathan Hogins, You-Cyuan Jhang, Mohsen Kamalzadeh et al, “Unity perception: Generate synthetic data for computer vision,” arXiv preprint arXiv:2107.04259 (2021).
Zack Sharf, “Marie Kondo Has ‘Kind of Given Up’ on Tidying Up: ‘My Home is Messy’,” Variety, January 27, 2023. See ➝.
Ron Amadeo, “The $1,600 Dyson 360 Vis Nav promises to be the world’s most powerful robovac,” arstechnica, May 23, 3023. See ➝.
Eileen Guo, “A Roomba recorded a woman on the toilet. How did screenshots end up on Facebook?,” MIT Technology Review, December 19, 2022. See ➝.
Julian Posada, “Family Units,” Logic(s), December 25, 2021. See ➝.
James Vincent, “iRobot’s newest Roomba uses AI to avoid dog poop,” The Verge, September 9, 2021. See ➝.
Stephan R. Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun, “Playing for data: Ground truth from computer games,” Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14 (Springer International Publishing, 2016): 102-118.
Wenbin Li, Sajad Saeedi, John McCormac, Ronald Clark, Dimos Tzoumanikas, Qing Ye, Yuzhong Huang, R. Tang and Stefan Leutenegger, “InteriorNet: Mega-scale Multi-sensor Photo-realistic Indoor Scenes Dataset,” British Machine Vision Conference (2018).
Simone Niquille, “On flatpack furniture and .zip folders,” CCA, October 18, 2021. See ➝.
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru, “Model cards for model reporting,” Proceedings of the conference on fairness, accountability, and transparency (2019): 220-229.
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford, “Datasheets for datasets,” Communications of the ACM 64, no. 12 (2021): 86-92.
David Marchese, “An A.I. Pioneer on What We Should Really Fear,” New York Times, December 21, 2022. See ➝.
Flickr30k image dataset introduced in Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier, “From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions,” Transactions of the Association for Computational Linguistics 2, (2014): 67–78. See ➝. Flickr Faces High-Quality (FFHQ) is a dataset of Flickr face photos originally created for face generation research by NVIDIA in 2019. It includes 70,000 total face images from 67,646 unique Flickr photos.(…) The images in FFHQ were taken from Flickr users without explicit consent and were selected because they contained high quality face images with a permission Creative Commons license.(…) The problem with NVIDIA’s proposed “opt-out” system is that no one ever opted in.” See ➝. In 2023 Apple introduced Object Capture, a photogrammetry API to effortlessly create high-quality 3D models, but its functionality is limited to Apple hardware with dual-lenses. See ➝.
Rob Runesson, “The content revolution to come,” Medium, November 20, 2020. See ➝.
Tom Solberg, “Transforming animation with machine learning,” Medium, February 26, 2021. See ➝.
LiU Game Conference, “EMBARK STUDIOS: Machine Learning For Believable AI Characters,” YouTube Video, 55:58, March 23, 2022. See ➝.
William Labov, “The boundaries of words and their meanings,” Bas Aarts, David Denison, Evelien Keizer, and Gergana Popova (eds.), Fuzzy grammar: A reader (Oxford: Oxford University Press, 2004).
Alex Hanna and Tina M. Park, “Against scale: Provocations and resistances to scale thinking,” arXiv preprint arXiv:2010.08850 (2020).
Impostor Cities is a collaboration between e-flux Architecture and The Museum of Contemporary Art Toronto within the context of its eponymous exhibition, which was initially commissioned by the Canada Council for the Arts for the 17th Venice Architecture Biennale.







